
A fifth of the world’s oil is in danger
The risk to the oil of the Middle East


Our goal with The Daily Brief is to simplify the biggest stories in the Indian markets and help you understand what they mean. We won’t just tell you what happened, we’ll tell you why and how too. We do this show in both formats: video and audio. This piece curates the stories that we talk about.
You can listen to the podcast on Spotify, Apple Podcasts, or wherever you get your podcasts and watch the videos on YouTube. You can also watch The Daily Brief in Hindi.
In today’s edition of The Daily Brief:
The risk to the oil of the Middle East
Small models, big economics
The risk to the oil of the Middle East
If you’re anything like us, you’ve probably spent the last few days hitting refresh continuously across the news, Twitter and Reddit, trying to understand what the hell is going on in the Middle East.
We have no idea how an event like this plays out, and how it could touch us, here in India. We don’t know what to anticipate. There are various possibilities, big and small, that are worth considering: from what happens to the Middle East as an aviation hub, to whether trade routes between India and the West choke again, to whether our exports to the Middle East get compromised, to what an incident like this means for our foreign exchange reserves, and so on.
The most obvious, though, is that oil could suddenly become expensive. That’s already visible in the charts.
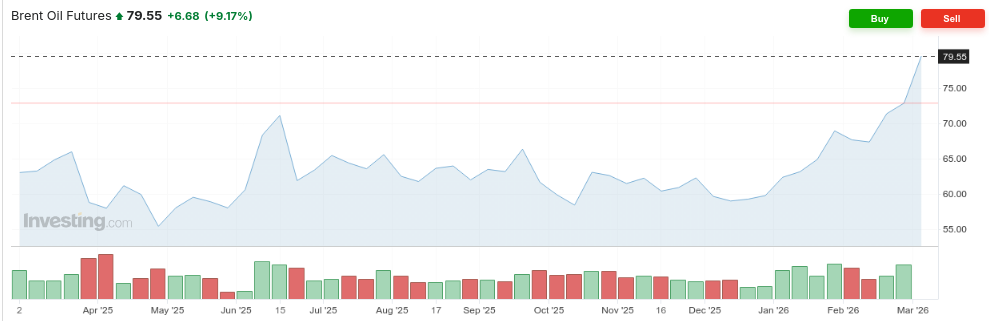
Prices, though, are an abstraction. They condense, into a single number, what the market feels about the overall level of risk that the world’s oil supply is under. That neat picture flattens a mess of physical realities: where individual oilfields, ports, ships, and more all face different threats if the war escalates.
To really sense what the risks are, it’s helpful to understand where the Middle East’s oil infrastructure actually sits. Only then can you understand the specific places where things can go seriously wrong.
A word of caution: we’re writing about this on Monday. By the time you come across this, the whole landscape could look very different. The war could escalate, they could reach some sort of ceasefire, some of the infrastructure we mention could already be taken out, more countries could be pulled in... and so on. Forgive us for anything that slips us by.
The map, as it stands
Let’s begin by looking at the Middle East. At its heart sits the Arabian peninsula. This massive arid landmass is particularly interesting because of its edges. These edges shape everything about how the region’s oil reaches the world.
To the peninsula’s east is the Persian Gulf — a long, narrow channel which is almost pinched shut, before it opens through the Strait of Hormuz into the Arabian Sea. On the other side of this channel is Iran. To the west, the Red Sea marks an even longer corridor between the peninsula and Africa. Its southern tip tapers down into a tiny opening — the Bab-el-Mandeb strait — before opening into the Indian Ocean.
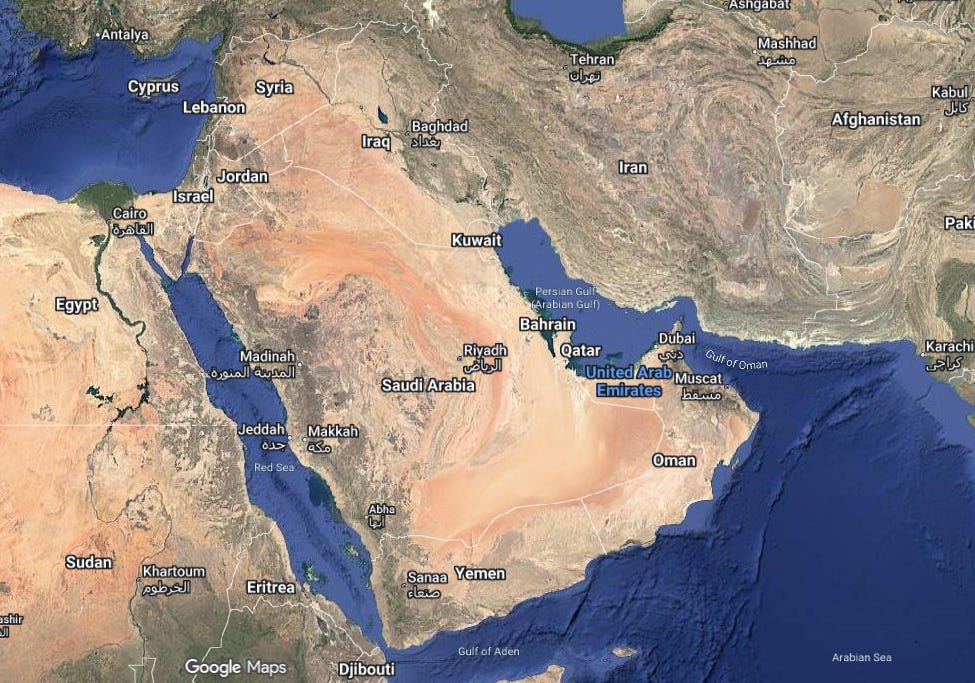
We’ll come back to this repeatedly.
This part of the world holds nearly half of the world’s proven oil reserves. But those aren’t spread all across the Middle East. Instead, they’re clumped together in a thin band around the Persian Gulf — the Eastern channel we spoke about. They either lie inside Iran, or across a narrow sea from it. This region, now, is the epicentre of this conflict.
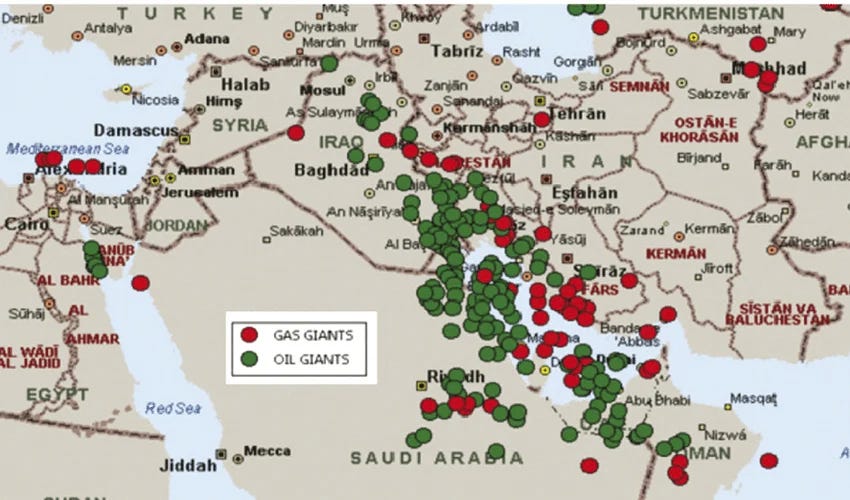
The producers
The biggest of the region’s oil producers — the load-bearing pillar of the Gulf oil system — is Saudi Arabia. There are over 250 billion barrels of oil under its sands, and the kingdom pulls out 9-10 million of them a day. It also has a lot of spare capacity. If it’s ever necessary (or profitable) to do so, it can add another 3 million barrels every day to its output.
Most of that oil, however, comes from a thin strip at the Eastern edge of the country.
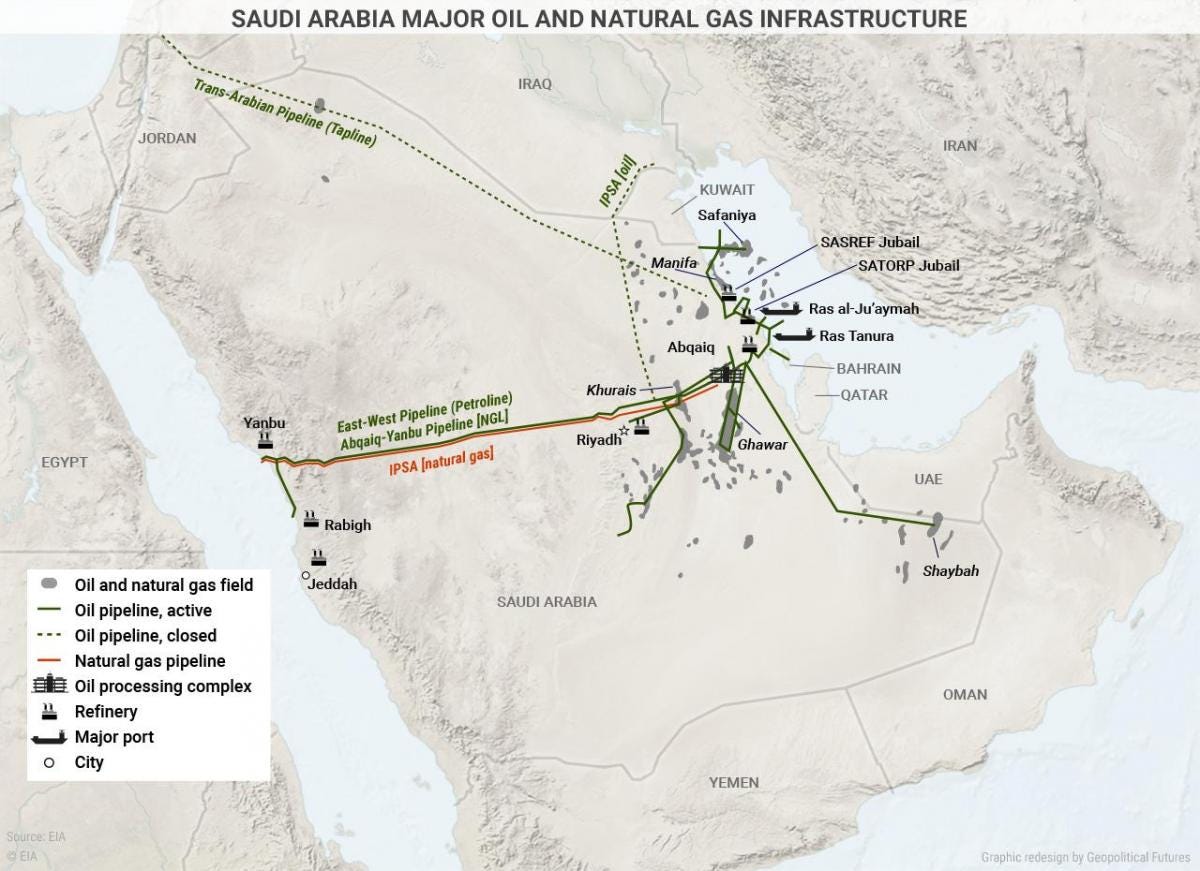
Nearly a third of that output comes just from Ghawar, the world’s largest conventional oilfield. Other fields, too, lie in the vicinity. They’re all within 300 km of Iran — well within the range of its missiles.

Much of that oil is funneled into a single node: the Aqbaiq processing facility: where sulphur impurities are stripped out of the region’s sour crude, to make it sweet. Nearly 7% of the world’s oil passes through this single facility every day. That also makes it a target for drone attacks, as the kingdom learnt in 2019.

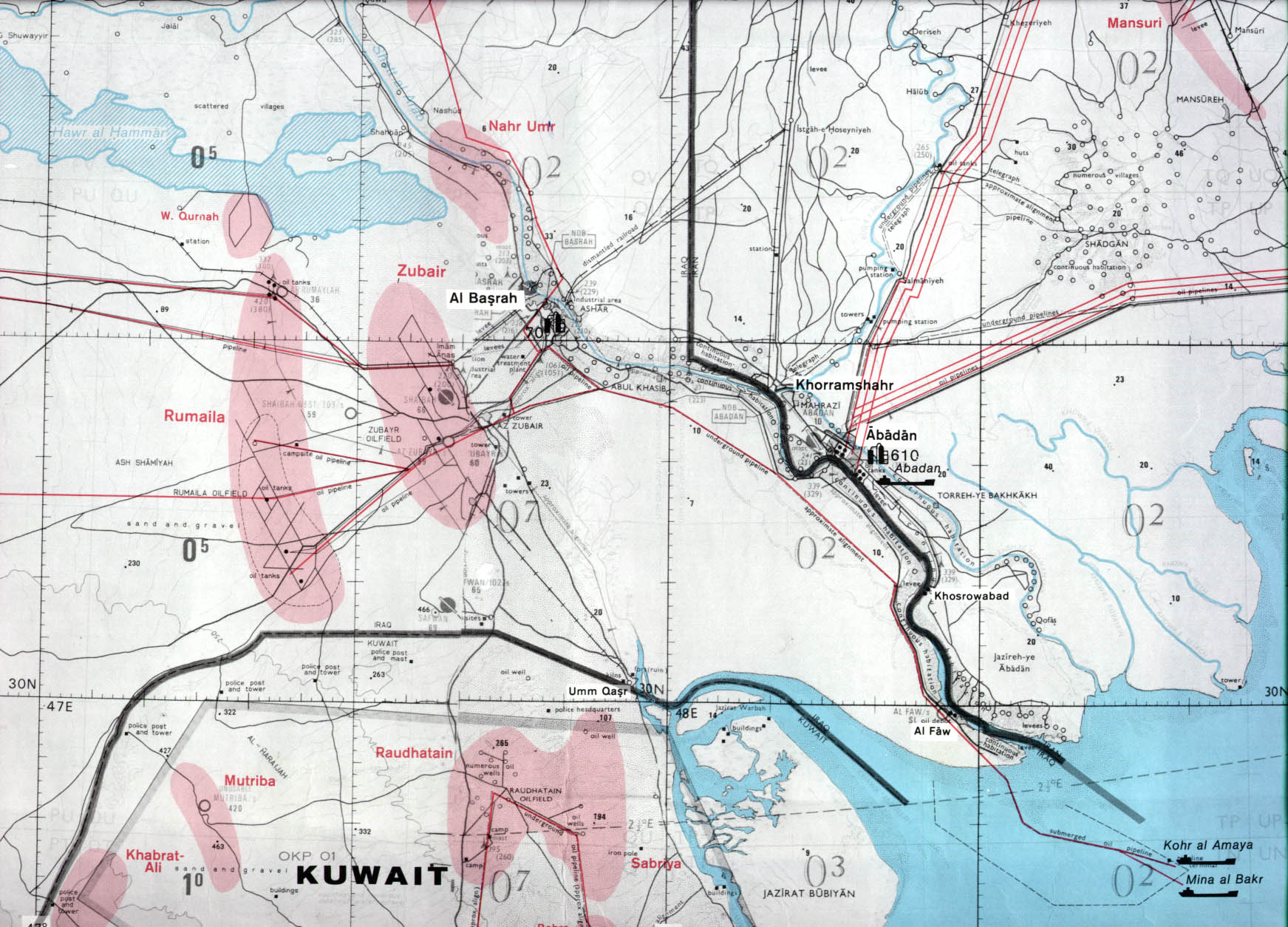
The region’s other oil producers are all concentrated nearby. The second-largest oil producer in the Middle East is Iraq, which pushes out around 4.5 million barrels every day. Most of its oil fields sit at its Southern tip, at Basrah, which opens through a narrow corridor into the Persian Gulf.
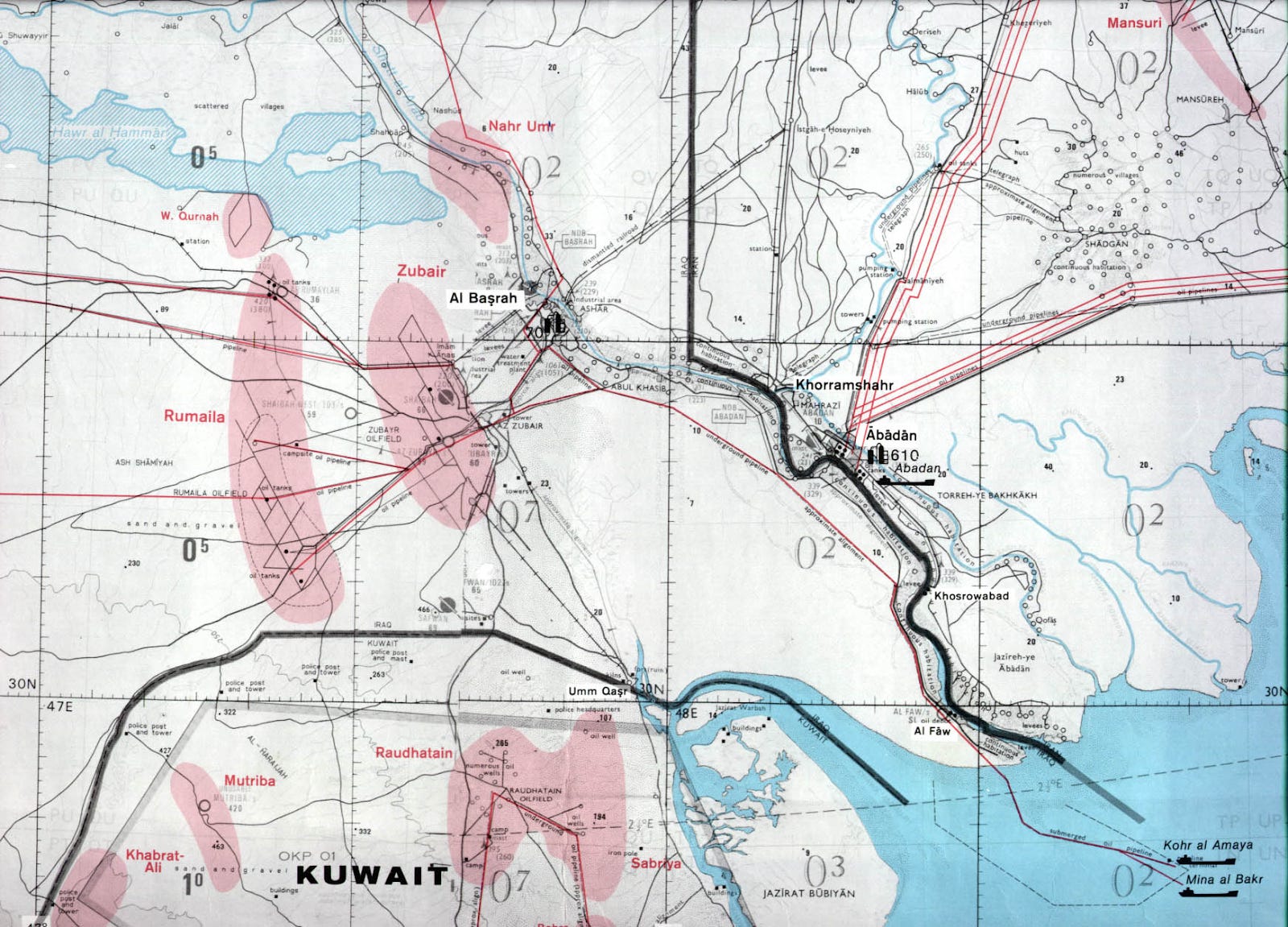
Just below, to the West of the Gulf is Kuwait, which produces ~2.5 million barrels of oil a day. Lower down, along the edge of the Gulf, is Qatar — which produces a relatively modest 600,000 barrels a day, along with 1.3 million barrels of natural gas. Below that is the United Arab Emirates, with an output of just under 3 million barrels a day.
On the other side of the conflict, Iran’s oil-bearing regions too line the same Gulf. Most of its oil reserves sit at the very north of the Gulf, in its Khuzestan province. While it has been under severe sanctions for decades, the country manages to export a substantial amount of oil itself, through an extensive shadow economy.
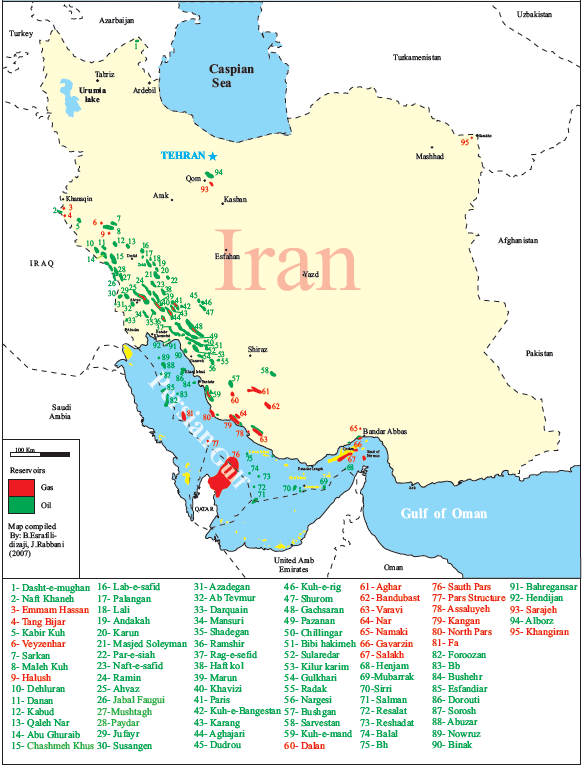
Realistically, there’s only one major oil producer that sits outside this Gulf: Oman. But right now, Oman produces less than a million barrels of oil per day — making it a rather minor player compared to its peers.
How that oil gets out
This all boils down to one fact: a stupendous amount of the region’s oil infrastructure — and frankly, that of the entire world — borders a single sea. All along the Persian Gulf’s roughly 5,000 kilometer coastline is a stupendous network of oil wells, refineries, terminals, and more. Almost all of the Middle East’s oil exports begin their journey in this Gulf.
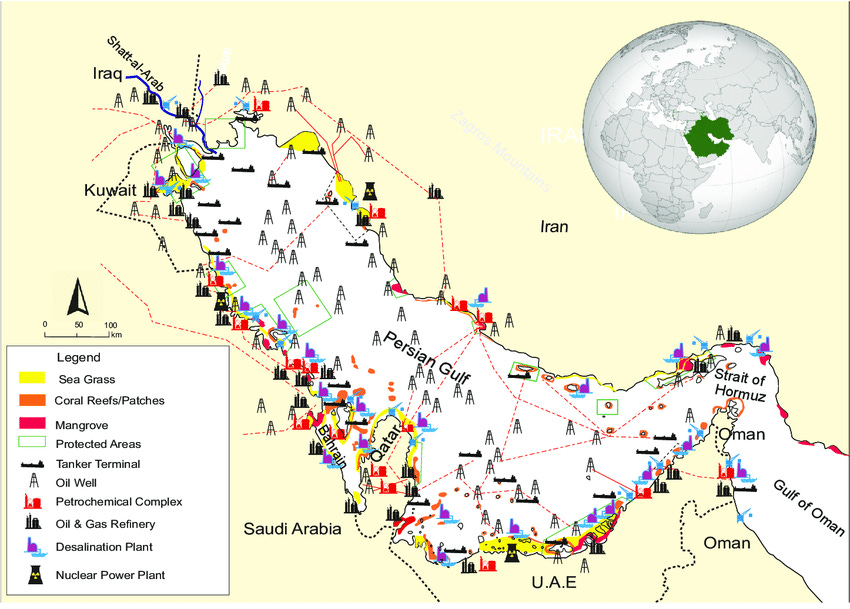
That, as we’ll soon discover, is incredibly important.
The region’s smaller countries have almost no way of by-passing the Gulf. All the oil from Iraq, Kuwait and Qatar exclusively goes through the Persian Gulf.
In theory, Iran has a way of getting around the Persian Gulf, through pipelines that cross the entire region and open into Jask, right below. But that port is practically out of commission. Most Iranian oil — over 90% — is exported out of the island of Kharg, in the Persian Gulf.

There are, in fact, only two ways to by-pass the Gulf.
The first is Saudi-Arabia’s East-West Oil Pipeline, or the Petroline. This cuts right across the Arabian desert, running for over 1,200 km. It begins at Aqbaiq, Saudi Arabia’s central oil processing hub, and from there stretches to both coasts. At the Eastern end, it reaches the Ras Tanura/Ju’aymah export complex, into the Persian Gulf.
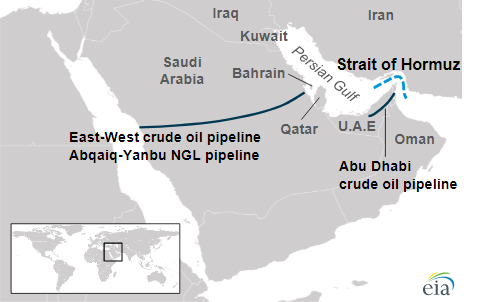
The other end, however, runs all the way to Yanbu at the West, by the Red Sea. On a good day, these pipes carry 5 million barrels of oil. But ever since Houthi attacks have put the Red Sea in danger, the line has been at 80-90% capacity. Effectively, if the Gulf no longer is an option, these pipes can at most carry a million barrels a day.

The UAE, too, has a pipeline of its own — the Abu Dhabi Crude Oil Pipeline. This carries oil from its onshore oil fields to just below where the Persian Gulf ends, at Fujairah. Only, this pipeline, too, is running at over 70% capacity. In a pinch, that just leaves half a million barrels of daily capacity.

A litany of chokepoints
When they say that a war in the Middle East could hurt oil markets, here’s what they actually mean: there are a series of chokepoints strewn across the region which are critical to the world’s oil supply. And at the moment, all of those chokepoints are in play.
The Straits
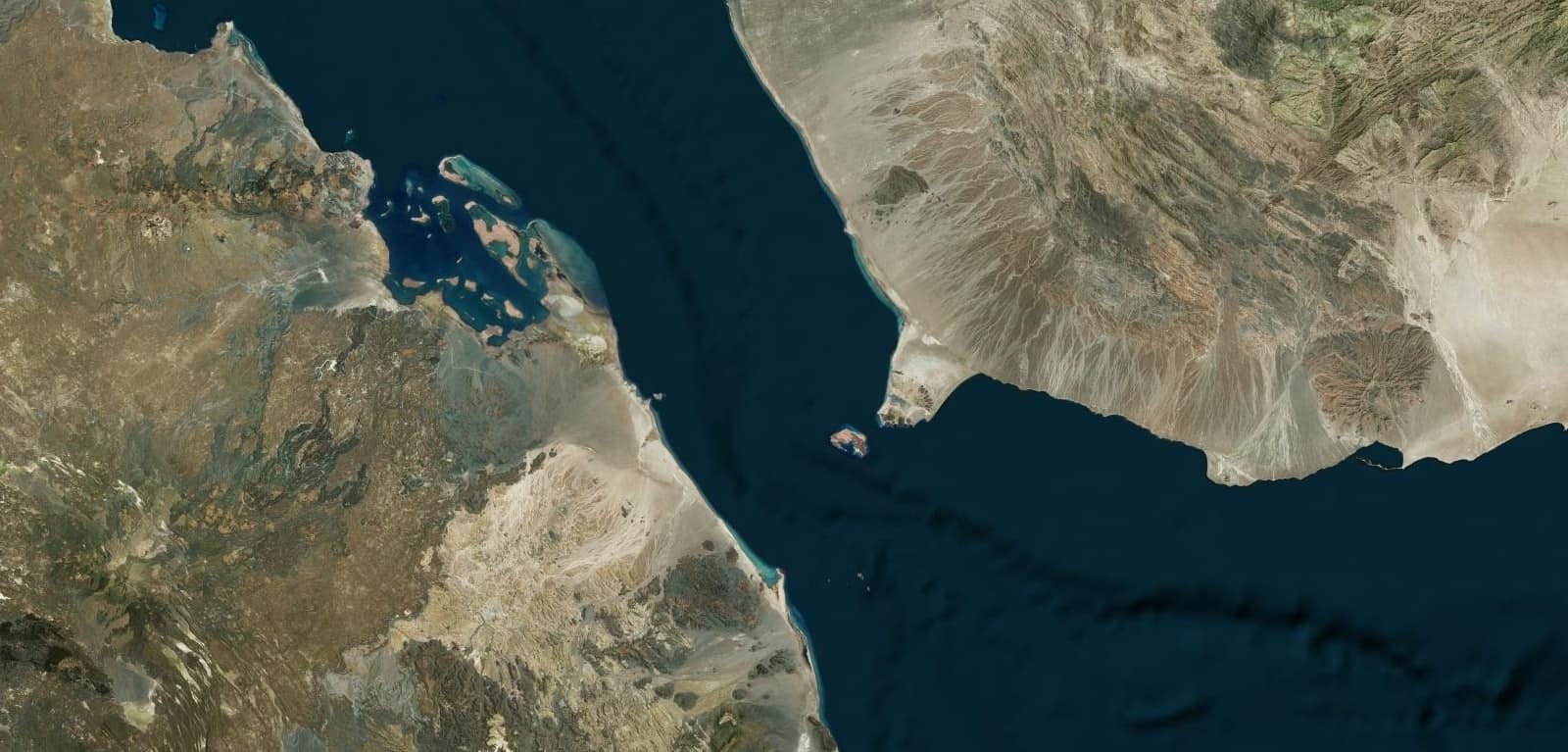
The most consequential of these is at the edge of the Persian Gulf, where the Arabian Peninsula juts out, like a horn, towards Iran. This is the Strait of Hormuz. At this point, which stretches for three kilometers, the waterway suddenly narrows. Its width — from over 200 km at its widest point, drops to just 33 km.

All of the Persian Gulf’s oil — more than 20 million barrels per day, or roughly 20% of the world’s supply, and one-fourth of the oil carried through the seas — passes through this one chokepoint. That is over half a trillion dollars worth of energy products a year. Cut this off, and you can break the back of the world’s oil trade.
Iran’s position, here, is incredibly strong. It has built a range of defences — naval mines, anti-ship missiles, fast attack boats, drones, and more. Should it ever decide so, the country can choke this strait in a few hours.
But Iran doesn’t need to choke this spot. It simply needs to create a credible threat that it will, and the commercial logic of crossing this point collapses.
At the time we write this, that already seems to be underway. Over the last two days, three commercial ships came under attack. Since then, many commercial operators have suspended all operations through the Strait. Over 150 tankers are stranded inside.

Meanwhile, insurers have essentially refused to give war insurance to any ship plying the route. That effectively kills any scope for commercial shipping in the region.
There are few alternatives. In theory, Saudi Arabia can push oil out of Yanbu, at its Western Coast, and into the Red Sea. But separating the Red Sea from the Arabian Sea is another such chokepoint — the Bab el-Mandab. This point has already been under pressure for a few years, from Houthi rebels that are allied with Iran. That just leaves the UAE’s pipelines out of Fujairah, but those have limited capacity.
Other infrastructure
Meanwhile, there are other pressure points, even if they aren’t this absolute. Almost all of the region’s oil production and infrastructure is within the reach of both side’s missiles. All of it is at risk.
There are places where that risk concentrates.
For instance, oil from several fields in a region can funnel into a single refinery, which processes lakhs of barrels a day. If an attack forces that capacity offline, the entire supply chain can drag to a halt, even if there’s oil to move at the wellhead. Recently, for instance, Iranian drones attacked Saudi Arabia’s biggest oil refinery at Ras Tanura. The city also contains its biggest oil terminal. The refinery has now been shut.

Every step of the supply chain presents something similar. For instance, the Saudi facility at Aqbaiq — which “sweetens” 7 million barrels of crude oil a day — may well be the single most critical point in the world’s oil infrastructure. If the facility is damaged, the world could lose a few percentage points of oil capacity for months.
Oil is always a global story
This is a delicate moment for the world’s oil markets. There is a very real risk that one-fifth of the world’s oil supply could disappear, if the conflict carries on for long. If the conflict lasts for a short while, the world’s reserves can shrug this moment off. If it carries on, however, you might see prices rise slowly.
This comes at a time when oil facilities, as a whole, are turning into targets. Only recently, for instance, Ukrainian drones attacked a major Russian oil terminal. At moments like this, while the damage might be limited to the country that was attacked, the costs carry over to the rest of the world.
That is particularly bad news for a country like India, which imports most of its oil. We’re currently scrambling for options. Shortly after our attempt to pivot away from Russian oil, for instance, we might embrace it again.
This story is changing rapidly. There’s nothing we can say for certain. But good news, like oil, might soon be in short supply.
Small models, big economics
The next time you ask your phone’s AI assistant to draft a quick reply, consider what’s actually happening under the hood.
Your words travel to a data centre — possibly on another continent. There, a model the size of a small library processes them, generates a two-line response, and sends it back. Everything happens in a couple of seconds, using a small slice of a very expensive GPU.
All for something like: “Sounds good, let’s do Thursday.“
There is a growing school of thought that considers this absurd. Not because the technology doesn’t work, but because it’s a bad architecture for the job. Calling on frontier AI models — the ones that can get AIR 4 in India’s toughest exams — to summarize your emails is like using a rocket to kill an ant. Sure, it works. But it’s overkill.
What if the model that drafted that reply lived on your phone. It would be smaller, faster and private. And after the initial setup, it would essentially run for free. That’s the promise of Small Language Models, or SLMs. And the debate between SLMs and their giant cousins — Large Language Models, or LLMs — is becoming a consequential economic question in tech.
But to understand why, you need to understand how these models actually work, and where the money goes. For that, you need to get comfortable with three ideas: parameters, inference, and tokens.
The engine inside a language model
A language model — ChatGPT, Google’s Gemini, Anthropic’s Claude — is, at its core, a machine that takes text in and spits text out. To do so, it uses a ridiculous number of adjustable dials. Each dial is a number — or a “parameter”. Big models can have hundreds of billions of them.
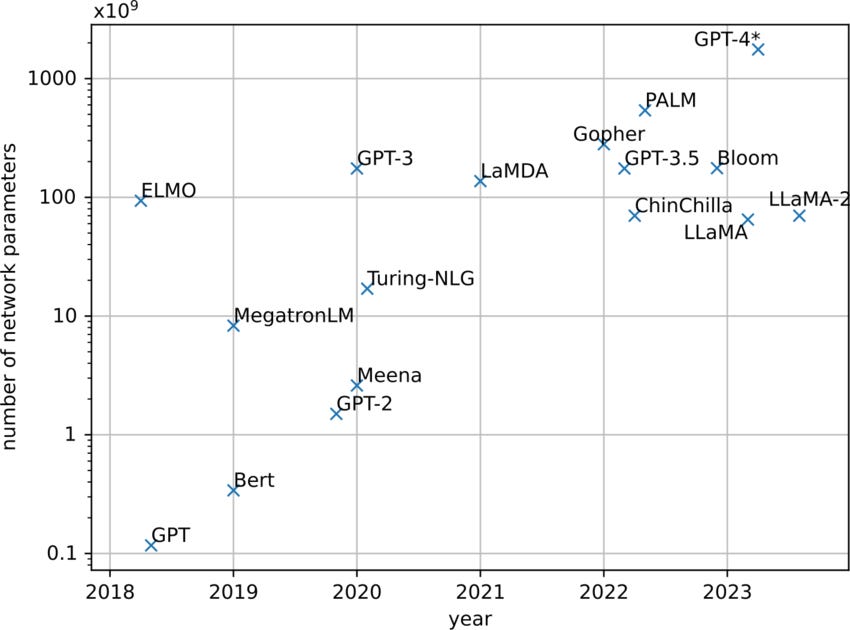
What do these parameters do? They control how strongly the model leans toward one meaning over another. Think of it like this: every word has its own meaning, of course, but by itself, that meaning is ambiguous. It shifts based on the words around it. Models “learn” those shifts, and the patterns get stored across parameters.
Imagine you ask ChatGPT something like: “what should one do if the economy is overheating?” It needs to realise that the word overheating, here, has nothing to do with heat at all — or else, it’ll ask you to turn on the air conditioning, instead of fighting inflation. There are infinite such examples in any language, when you infer a word’s meaning from what is around. It’s nearly impossible to hard-code rules for every single possibility. But a model recognises that when “economy” and “overheating” come near each other, things like “interest rates” or “inflation” are around the corner.
The model stores such things as mathematical relationships, based on billions of examples of human text. Think of it as preparing a giant graph of how all words connect to each other — except that instead of just an X and a Y axis, it has thousands of axes over thousands of dimensions.
With such a huge, complex graph, it can map language out in many ways. It can understand what the same word does in different contexts, or how the sentence’s tone changes it, or how polite it is, or the emotional effect it has, and so on.
Models don’t think in terms of words, though: they think in tokens. A token is just a chunk of text — sometimes a whole word, sometimes part of one, sometimes something else entirely, like a space or a punctuation mark. The word “India”, for instance, might be a single token. But a word like “unbreakable” could be split into three, like “un-”, “break”, and “-able.” It is at this level that the model draws its relationships.
There are two phases in a model’s life. Understanding them is essential to understanding AI economics.
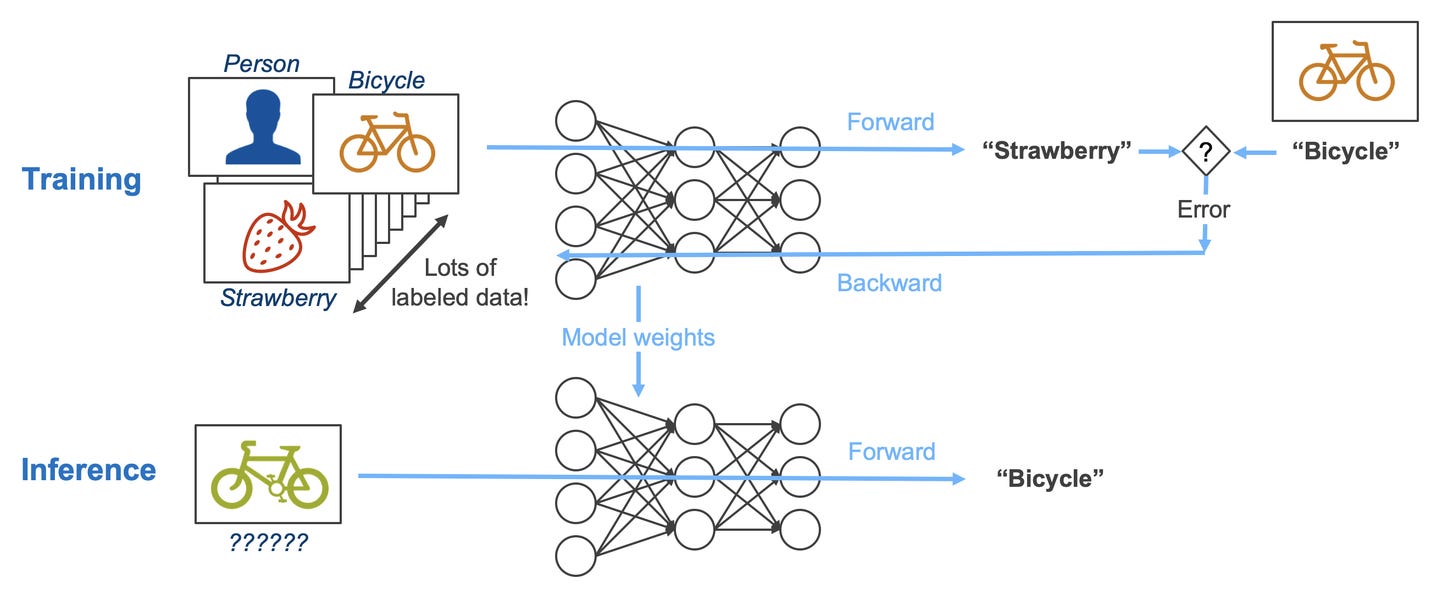
Training is the learning phase. The model reads absurd amounts of text and plays one game on repeat: “Given what I’ve seen so far, what token comes next?” In the beginning, it guesses completely at random, and gets it entirely wrong. But with every wrong guess, it nudges its parameters to be slightly less wrong the next time. Over trillions of attempts, the model gets “educated.” Training is brutally expensive — GPU chips running for weeks or months at an end — but it’s mostly a one-time cost.
After training, the model’s parameters are locked. Then, you turn to inference — when you actually use the model. When you ask a question, the model isn’t learning anything new; it’s using what it already learned to generate an answer.
{kind=link}
{kind=link}
{kind=link}
Training costs a lot per run, but those runs happen occasionally. Inference is cheap per query but happens every time someone uses your model. This defines the economics of each.
Why bigger models cost more to run
Imagine a model has 70 billion parameters. For that to be useful, the GPU must be able to call on them quickly — and so, each parameter must sit in GPU memory at each step of inference. Usually, 70 billion parameters take up roughly 140 gigabytes. A single high-end GPU might have 40 to 80 GB. So, the larger your model is, the more GPUs must work together to run it. That means more hardware, more electricity, and more infrastructure. Meanwhile, a smaller model — say, 3 billion parameters — could fit comfortably on a single GPU.
Then, the GPU must actually work through those parameters. It begins with the input you give it, and then starts running its calculations, navigating through the web of relationships it has stored. The longer your prompt, the more work it has to do in pushing out an output. And every output token is the result of a massive number of mathematical operations, using those parameters. The more the parameters, the more math calculation done per token.
So inference cost grows along three axes: model size (how many parameters), input length (how many tokens you send), and output length (how many tokens the model generates back).
When bigger isn’t better
We’ve met the LLMs — the giant models in data centres. Small Language Models sit at the other end: roughly 100 million to 5 billion parameters, though that boundary is fuzzy and shifts over time. They can be so small, in fact, that they might not need data centres at all; they could be compact enough to run on your phone, laptop, or local server. Think of Google’s Gemini Nano (built into Pixel phones), Apple’s on-device models, or Microsoft’s Phi series.
This comes with trade-offs, of course. They’re fast, cheap, and private, but they’re less capable of complex, open-ended tasks. And the smaller the model, the more you’re sacrificing.
If all else were the same, you might always choose more capability, no matter how small your task is. But if you’re a business that’s deploying an AI model, you’re asking more complex questions: like where the model runs and what that implies. You want to know what each query costs, how fast it comes, if it works when there’s no internet, what happens when the model gets it wrong, and so on.
Energy: the quiet ceiling
GPUs drink electricity. Research on a 65-billion-parameter model shows that every million output tokens of inference can use ~0.83 to 1.11 kWh. As AI services handle hundreds of millions of queries daily, those energy needs add up — enough that they’re turning into a serious macro problem in places like the United States. In 2024, data centres consumed about 415 terawatt-hours of electricity — roughly 1.5% of global demand. And AI demand has only exploded since.
When you run a small model on your phone or laptop, on the other hand, you no longer have to ship it to a data centre and back. That means the energy needed per query drops sharply. Some research suggests on-device inference can use up to ~95% less energy and cut carbon footprint by ~88% versus cloud GPUs. That directly lowers the cost of each query.
Then, there’s security. If your prompt isn’t being sent to a server halfway across the world, you’re not relying on someone else’s systems, policies, or legal jurisdiction to keep it safe. You keep more control by default.
When seconds become minutes
So far, we’ve talked about why you might prefer a small on-device model instead of a large one. But even among SLMs, you might not always want to run the largest models.
Imagine, for instance, that you were designing a mobile game, with realistic characters that you could talk to. If they were powered by a small model, they could manage basic dialogue, and could emote to a basic level — but when you talked to them for long enough, the edges would show. A larger model, in contrast, could come up with lots of dialogue, creating the impression that all characters lived rich inner lives.
What’s the better choice? The larger one?
Well, there’s a constraint. A study benchmarking models on a Samsung Galaxy S24 measured Time to First Token, or TTFT: how long the model takes to start responding. For an 8-billion-parameter model on that phone, TTFT was roughly 261 seconds just to begin answering a simple question. That is, if you started speaking to a character, they would respond 4 minutes later. Smaller models in the 100-million to 500-million range? Sub-second to single-digit seconds.
The choice is obvious. If a model takes four minutes to even start, it can’t be part of anything interactive. Latency, in cases like this, is a hard gate on whether the tool creates value at all.
The decision framework
So, what model does a business use, and when? You can think about it as a simple equation:
Total Cost = Inference Cost + Integration Cost + Expected Loss + Governance Cost.
On the one hand, you want to lower your inference cost. Bigger models simply cost more.
You also want to be mindful of integration costs. You need to make sure the model actually sits well within your workflows, and doesn’t eat up a lot of time and resources to work with. For instance, if you have a lot of use-cases, a large model might be able to “one-shot” all of them, whereas you might have to spend a lot of engineering time in customising a small model for everything. On the other hand, if you want a dependable system that does one thing quickly and reliably, it might not be a good idea to depend on a large model that changes its behaviour with every update.
Then, there’s the expected loss. How often will the model be wrong, and how bad is it when it’s wrong? Would a human catch the error, or will it slip by easily? If a model hallucinates a financial summary and that feeds into an investment decision, for instance, you could face serious losses: much larger ones than your token bill.
Finally, there’s a governance cost — the effort required to make the system safe enough to deploy. If you’re self-hosting a smaller model, with narrower use cases, you can build in controls — like audits, or redundancies. They’re generally easier to reason about and test. Larger, more complex models are harder to fully understand and control.
With that lens, the trade-off becomes clearer. There’s no single answer to what’s the better choice; Everything boils down to how you operate: how many questions you need answered, how fast, what the stakes are, and so on. With all this, it boils down to a unit economics and risk management choice.
SLMs win when the workload is high-volume, speed-sensitive, offline-friendly, or privacy-heavy. It helps you with predictable, standard responses. Think millions of small queries where cost and latency matter more than brilliance.
LLMs win when the task is open-ended, messy, or novel — and capability actually translates into results. It also helps when you want to avoid dumb mistakes in edge cases. That’s when you pay the premium.
Hybrid is the default?
This isn’t a binary choice, though. Often, the most sensible set-up is a hybrid one.
A small on-device model can act as the front gate. It can figure out intent, run safety checks, strip away sensitive data, and answer the easy stuff locally. The genuinely hard cases — which need deep reasoning or long context — get then be escalated to a cloud LLM.
As things move on, we expect to see a lot of creativity in how different models will be brought together. Perhaps, then, the models will feel instant and seamless, and yet, could be as smart as the best tools you’ve seen so far.
Tidbits
Gold loans double share in bank retail credit
Gold loans now make up 6% of banks’ retail portfolios, up from 3% a year ago, as soaring gold prices boosted demand. Overall retail credit grew 14.9% in January, but credit card growth slowed sharply to 1.5%. MSME lending remained strong, helping lift overall bank credit growth to 14.6%.
Source: Business StandardAmazon India scraps referral fees on products under ₹1,000
Amazon will stop charging seller referral fees on products priced below ₹1,000 from March 16. The move expands last year’s zero-fee policy and now covers over 125 million products. It aims to attract more small sellers as competition intensifies from Flipkart, Reliance and quick-commerce players.
Source: ReutersVisible pickup in private investment cycle: Das
Shaktikanta Das said Indian companies are financially stronger after years of deleveraging, with cleaner balance sheets and better profitability. He noted early signs of a revival in private investment. Stronger trade ties and digital transformation are expected to support the next phase of growth.
Source: Business Standard
- This edition of the newsletter was written by Pranav and Kashish.
We’re now on WhatsApp!
We’ve started a WhatsApp channel for The Daily Brief where we’ll share interesting soundbites from concalls, articles, and everything else we come across throughout the day. You’ll also get notified the moment a new video or article drops, so you can read or watch it right away. Here’s the link.
See you there!
Thank you for reading. Do share this with your friends and make them as smart as you are 😉
very well written, amid all the news, this was preciously what needed to understand whole story better
Ah! Nicely explained the oil/gas trade dynamics in Middle East and its relevance to geopolitics…. Detailed maps helped quite a bit to understand it better…also SLM/LLM distinction and its relevant to different devices was well elaborated…